Java面试题(7)- 线程安全
1 说说如何保证线程安全?
当多个线程访问某个方法时,不管通过怎样的调用方式或如何交替的执行,都能得到我们理想中的结果,可以说这个类是线程安全的。线程不安全就是不提供数据访问保护,有可能出现多个线程先后更改数据造成所得到的数据是脏数据。
保障线程安全的方法有六种:
- 使用线程安全的类:如ConcurrentHashMap、Vector、Java.util.concurrent.atomic包下的原子类 AtomicXXX等等。
- 使用synchronized或者锁:采用同步控制的关键字或者类,比如synchronized、ReentrantLock、# ReentrantLock等等。
- 采用不可变设计:如果在并发环境中不得不设计共享变量,则应该优先考虑共享变量是否只读,如果是只读场景就可以将变量设计位不可变的。具体来说,就是在变量前加final修饰符,使其不可被修改,如果变量是引用类型,则将其设计为不可变类型。
- 使用并发工具类:java.util.concurrent包提供一些并发工具类:Semaphore,信号量,可以控制同事访问特定资源的线程数量;CountDownLatch,允许一个或多个线程等待其他线程完成操作;CyclicBarrier:让一组线程到达一个屏障时被阻塞,直到最后一个线程到达屏障时,屏障才会打开,所有被屏障拦截的线程才会继续进行。
- 使用本地存储:考虑使用ThreadLocal存储变量,为每一个线程单独存一份数据,将需要并发访问的资源复制成多份。这样一来就可以避免多线程访问共享变量了。
- 无状态设计:线程安全问题是由多线程并发修改共享变量引起的,如果在并发环境中没有设计共享变量,则自然就不会出现线程安全问题了。
2 如何实现一个线程安全的数据结构?
设计一个在多线程环境中使用的数据结构,通常基本API包括插入元素、删除元素、检索元素、检查元素是否存在。每个操作都必须考虑采用锁等机制保证单个API调用的原子性。
3 volatile关键字的作用是什么?
- volatile的作用
(1)线程的可见性
一个线程修改的状态对另一个线程是可见的,也就是一个线程修改的结果,另一个线程马上就能看到。
当对非volatile变量进行读写的时候,每个线程先从主内存拷贝变量到CPU缓存中,如果计算机有多个CPU,每个线程可能在不同的CPU上被处理,这意味着每个线程可以拷贝到不同的CPU cache中。volatile变量不会被缓存在寄存器或者对其他处理器不可见的地方,保证了每次读写变量都从主内存中读,跳过CPU cache这一步。当一个线程修改了这个变量的值,新值对于其他线程是立即得知的。
(2)禁止指令重排序
代码在实际执行过程中,并不全是按照编写的顺序进行执行的,在保证单线程执行结果不变的情况下,编译器或者CPU可能会对指令进行重排序,以提高程序的执行效率。
double r = 2.1; //(1)
double pi = 3.14;//(2)
double area = pi*r*r;//(3)以上代码语句的定义顺序为1->2->3,但是计算顺序1->2->3与2->1->3对结果并无影响,所以编译时和运行时可以根据需要对1、2语句进行重排序。我们再看看加了volatile的双重校验锁单例模式代码:
public class Singleton {
public static volatile Singleton singleton;
private Singleton() {};
public static Singleton getInstance() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}这里为什么要加上 volatile 修饰呢?先了解对象的创建过程,实例化一个对象分为三个步骤:A.分配内存空间;B.初始化对象;C.将内存空间的地址赋值给引用。由于编译器可以对指令进行重排序,上面的过程也可能变成如下过程:A.分配内存空间;B.将内存空间的地址赋值给引用;C.初始化对象。多线程环境下将一个未初始化对象的引用暴露出来,可能导致不可预料的结果。为了防止这个过程的重排序,需要将Singleton 变量修改为volatile类型。
volatile防止指令重排序是通过内存屏障来实现的。编译器在生成字节码文件时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。内存屏障分为如下三种:
Store Barrier: Store屏障,是x86的”sfence“指令,强制所有在store屏障指令之前的store指令,都在该store屏障指令执行之前被执行。
Load Barrier: Load屏障,是x86上的”ifence“指令,强制所有在load屏障指令之后的load指令,都在该load屏障指令执行之后被执行
Full Barrier: Full屏障,是x86上的”mfence“指令,复合了load和save屏障的功能。
Java内存模型中volatile变量在写操作之后会插入一个store屏障,在读操作之前会插入一个load屏障,并且volatile修饰的变量的读写指令不能和其前后的任何指令重排序,其前后的指令可能会被重排序。一个类的final字段会在初始化后插入一个store屏障,来确保final字段在构造函数初始化完成并可被使用时可见。也正是JMM在volatile变量读写前后都插入了内存屏障指令,进而保证了指令的顺序执行。
- volatile的问题
volatile不能完全保证原子性。 如果volatile修改的变量与以前的值相关,如n=n+1、n++等,volatile将失效。只有变量的值和自身上一个值无关时,对该变量的操作才是原子级别的,如 n = m + 1。
class TestVolatile {
volatile int n;
private void test1() {
n++;
n = n + 1;
}
private synchronized void test2() {
n++;
n = n + 1;
}
}上面的代码里面,test()方法不是原子操作。需要使用synchronized关键字变成原子操作,如test2()方法。
4 Java并发包提供了哪些并发类?
- Atomic:AtomicBoolean、AtomicInteger、AtomicLong、AtomicReference
类提供多种方法,可以原子性地为参数取值、赋值、交换值(getAndSet)、比较并且设置值(CAS:compareAndSet)等。 - Lock:ReentrantLock、ReentrantReadWriteLock等,可重入的互斥锁,即同一线程可以多次获得该锁。
- BlockingQueue:线程安全的阻塞队列,与普通队列(LinkedList或ArrayList)的最大不同点,在于阻塞队列提供了阻塞添加和阻塞删除的方法。常用的有ArrayBlockingQueue、LinkedBlockingQueue、DelayQueue等。
- BlockDeque:线程安全的双端阻塞队列,适用于生产者线程需要在两端生产 、消费者线程需要在两端消费的场景。
- ConcurrnetMap:ConcurrentHashMap是ConcurrentMap的具体实现,线程安全的HashMap
- CountDownLatch:允许一个或多个线程等待某些操作完成
- CyclicBarrier: 一种辅助性的同步结构,允许多个线程等待到大某个屏障
- ExecutorService:可以创建各种不同类型的线程池,调度任务运行等,绝大部分情况下,不再需要自己从头实现线程池和任务调度器
- CopyOnWriteList:一个线程安全的 ArrayList,修改操作是在底层的一个复制的数组(快照)上进行的,即用了写时复制策略。
- ThreadLocal:用于处理同一线程数据共享的操作类。目的减少参数传递,和不同线程之间的数据隔离
5 HashMap在多线程环境下使用需要注意什么,为什么?
HashMap底层的数据结构是数组+链表/红黑树,默认初始容量是16。当数组中的元素大于hashMap的初始容量乘以加载因子时(加载因子默认是0.75),HashMap就会进行扩容,容量变为原来的2倍,然后将原来的数据重新映射到新的桶里面,然后将原来的桶逐个置为null,使得引用失效。在hashMap进行扩容的时候容易发生HashMap线程不安全。
(1)在多线程的环境下,进行put()的时候会导致多线程的数据不一致。
例如有A、B两个线程,首先假设A获得CPU的执行权,A开始向HashMap中添加数据,先计算key的hash值,计算元素落到桶的索引坐标,然后获取到了桶里面的链表头结点,此时线程A的时间片用完了,线程B获得了cpu的执行权,线程B和线程A一样执行操作,只不过B成功的将元素添加到HashMap中了,此时线程A获得cpu执行权,假设A线程要插入的元素计算得到在桶中的索引和线程B插入元素的索引一样,线程B插入成功之后,线程A执行,此时线程A插入的数据会覆盖掉线程B插入的数据,这样线程B插入的记录就会凭空消失,造成了数据不一致。
(2)在多线程的环境下,执行get()元素的时候可能会因为扩容引起死循环
HashMap是采用链表解决Hash冲突,因为是链表结构,那么就容易形成闭合链路,这样在循环的时候只要有线程对这个HashMap进行get操作就会产生死循环。在单线程的情况下,只有一个线程对HashMap数据结构进行操作,是不可能产生闭合回路的,当put的时候,如果size>initialCapacity * loadFactor,那么这时候HashMap就会进行rehash操作,随之HashMap的结构就会发生翻天覆地的变化。很有可能两个线程就是在这个时候同时出发rehash操作,产生了闭合回路。
在多线程的环境下使用HashMap,考虑两种方法:
(1)使用ConcurrentHashMap
(2)使用Collections.synchonizedMap(Map<K,v> m)方法将HashMap变成一个线程安全的map。
6 ThreadLocal的作用与实现原理是什么?
ThreadLocal可以让线程拥有自己独享的变量,多个线程共享同一个ThreadLocal对象,但是每个线程都可以通过ThreadLocal的get方法获取或set方法设置属于该线程的变量副本,变量只属于该线程,并且其他线程无关。演示代码如下:
public class ThreadLocalId {
private final static AtomicInteger nextId = new AtomicInteger(0);
private final static ThreadLocal<Integer> threadId = new ThreadLocal<Integer>() {
// 重写ThreadLocal中的方法,用于如果没有通过set设置值时,第1次通过get来获取值时会调用这个方法生成初始值,可以重写该方法来指定初始值生成规则
@Override
protected Integer initialValue() {
return nextId.getAndIncrement();
}
};
public static Integer get() {
return threadId.get();
}
public static void main(String[] args) {
for(int i = 0; i < 5; i++) {
new Thread(new Runnable() {
@Override
public void run() {
int id = ThreadLocalId.get();
System.out.println("thread:" + Thread.currentThread().getName() + ",threadId-->" + id);
threadId.set(id);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("thread:" + Thread.currentThread().getName() + ",threadId-->" + threadId.get());
}
}).start();
}
}
}输出结果:
thread:Thread-0,threadId-->0
thread:Thread-1,threadId-->1
thread:Thread-2,threadId-->2
thread:Thread-3,threadId-->3
thread:Thread-4,threadId-->4
thread:Thread-4,threadId-->4
thread:Thread-2,threadId-->2
thread:Thread-1,threadId-->1
thread:Thread-0,threadId-->0
thread:Thread-3,threadId-->3以上代码开启5个线程,每个线程都调用同一个ThreadLocal对象threadId的get方法获取一个id值作为线程标识,并通过set方法保存到ThreadLocal中,然后再通过get方法来获取。每个线程虽然都是操作的同一个ThreadLocal对象,但是它们获取到的值并没有被其它线程覆盖,都是自己set进去的值。ThreadLocal通过提供线程本地变量,从而保证线程安全。
ThreadLocal内部是怎么保证对象是线程私有的呢?ThreadLocal包含两个最重要的方法set和get,先看看set方法的源码:
public void set(T value) {
Thread t = Thread.currentThread();
// 获取线程的ThreadLocalMap,返回map
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value); else
//map为空,创建
createMap(t, value);
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}当调用set方法时,其实是将数据写入threadLocals这个Map对象中,这个Map的key为ThreadLocal当前对象,value就是我们存入的值。而threadLocals本身能保存多个ThreadLocal对象,相当于一个ThreadLocal集合。与HashMap不同的是,ThreadLocalMap中的Entry是继承于WeakReference类的,保持了对 “键” 的弱引用和对 “值” 的强引用,看看类的源码:
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
//省略剩下的源码
....................
}再看看get方法的源码:
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
//设置初识值到ThreadLocal中并返回
return setInitialValue();
}
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value); else
createMap(t, value);
return value;
}get方法直接获取当前线程的ThreadLocalMap对象,如果该对象不为空就返回它的value值,否则就把初始值设置到ThreadLocal中并返回。
每个线程都维护着一个ThreadLocalMap的容器,可以保存多个ThreadLocal对象。调用ThreadLocal的set或get方法其实就是对当前线程的ThreadLocal变量操作,与其他线程是分开的,保证线程私有,也就不存在线程安全的问题了。该方案虽然能保证线程私有,但却会占用大量的内存,因为每个线程都维护着一个Map,当访问某个ThreadLocal变量后,线程会在自己的Map内维护该ThreadLocal变量与具体实现的映射,如果这些映射一直存在,就表明ThreadLocal 存在引用的情况,那么系统GC就无法回收这些变量,可能会造成内存泄露。针对这种情况,上面所说的ThreadLocalMap中Entry的弱引用就起作用了。
7 ThreadPoolExecutor的实现原理是什么?
ThreadPoolExecutor用于创建线程池。线程池是一种基于池化思想管理线程的工具,类似于连接数据库的连接池。在并发环境下,系统不能确定在任意时刻中,有多少任务需要执行,有多少资源需要投入。这种不确定性将带来若干问题:
(1)创建一个线程,操作系统要为线程分配一系列的资源,成本很高;
(2)频繁申请或者销毁、调度资源,将带来额外的非常大的消耗;
(3)对资源无限申请缺少抑制手段,易引发系统资源耗尽的风险;
(4)系统无法合理管理内部的资源分布,会降低系统的稳定性;
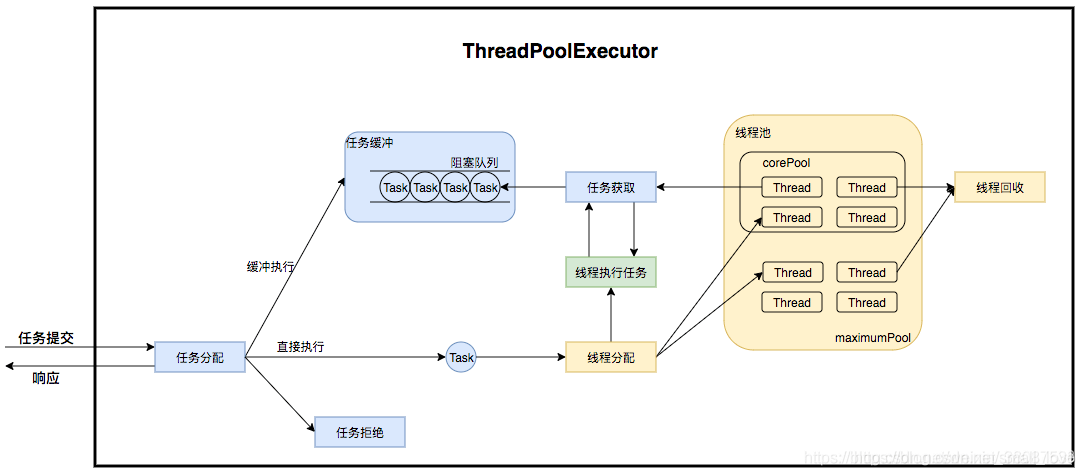
从上面流程图可以看出,线程池内部实际上构建了一个生产者消费者模式,将线程和任务两者解耦,并不直接关联,从而良好的缓冲任务,复用线程。线程池的运行主要分成两部分:任务管理、线程管理。任务管理部分充当生产者的角色,当任务提交后,线程池会判断该任务后续的流转:1)直接申请线程执行任务; 2)缓冲到队列中等待线程执行; 3)拒绝该任务。线程管理部分是消费者,它们被统一维护在线程池内,根据任务请求进行线程的分配,当线程执行完任务后则会继续获取新的任务去执行,最终当线程获取不到任务的时候,线程就会被回收。
8 什么是死锁,如何避免死锁?
-
死锁的定义
当两个或两个以上的线程因竞争相同资源而处于无限期的等待,就导致了多个线程的阻塞,出现程序无法正常运行和终止的情况,这就叫死锁。举个例子:小明和小张要玩一个玩具,这个玩具有两部分组成必须两部分组装起来才能玩,小明拿了第一部分,小张拿了第二部分;这时候小明等着小张给他第二部分进行组装玩,而小张也等着小明把第一部分给他进行组装玩;两个人都占用着资源谁也不给谁一部分,那么就出现了小明、小张都玩不成的情况 -
必要条件
(1)互斥条件:系统要求对所分配的资源进行排他性控制,即在一段时间内某个资源仅为一个进程所占有(比如:打印机,同一时间只能一个人打印)。此时若有其他进程请求该资源,则请求只能等待,直到有资源释放了位置;
(2)请求和保持条件:进程已经持有了一个资源,但是又要访问一个新的被其他进程占用的资源那么就会阻塞,并且对自己占用的一个资源保持不放;
(3)不剥夺条件:进程对已经获取的资源未使用完之前不能被剥夺,只能使用完之后自己释放。
(4)循环等待条件:存在一种进程资源的循环等待链,链中每一个进程已获得的资源同时被链中下一个进程所请求。 -
如何避免死锁
(1)保持加锁顺序:当多个线程都需要加相同的几个锁的时候(例如上述情况一的死锁),按照不同的顺序枷锁那么就可能导致死锁产生,所以我们如果能确保所有的线程都是按照相同的顺序获得锁,那么死锁就不会发生。
(2)获取锁添加时限:在获取锁的时候进行限时等待,例如wait(1000)或者使用ReentrantLock的tryLock(1,TimeUntil.SECONDS)这样在指定时间内获取锁失败就不等待;
(3)进行死锁检测:我通过一些工具检查代码并预防其出现死锁,比如JDK自带的jstack和JConsole工具。
9 Atomiclnteger的实现原理是什么?
AtomicInteger是对int类型的一个封装,提供原子性的访问和更新操作,其原子性操作的实现是基于CAS(compare-and-swap)技术。当利用CAS执行试图进行一些更新操作时,会首先比较当前数值,如果数值未变,代表没有其它线程进行并发修改,则成功更新。如果数值改变,则可能出现不同的选择,要么进行重试,要么就返回是否成功。也就是“乐观锁”。CAS是一种系统原语,JVM会帮我们实现CAS汇编指令。原语属于操作系统用语范畴范,是由若干条指令组成的,用于完成某个功能的一个过程。并且原语的执行必须是连续的,在执行过程中不允许被中断,不会造成数据不一致问题。
我们来看看AtomicInteger源码:
private volatile int value;
/*
* AtomicInteger内部声明了一个volatile修饰的变量value用来保存实际值
* 使用带参的构造函数会将入参赋值给value,无参构造器value默认值为0
*/
public AtomicInteger(int initialValue) {
value = initialValue;
}
再来看看incrementAndGet的源码:
import sun.misc.Unsafe;
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
/*
* 可以看到自增函数中调用了Unsafe函数的getAndAddInt方法
*/
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}incrementAndGet方法实际调用了unsafe.getAndAddInt()。Unsafe类是在sun.misc包下,不属于Java标准。但是很多Java的基础类库,包括一些被广泛使用的高性能开发库都是基于Unsafe类开发的,比如Netty、Cassandra、Hadoop、Kafka等。Unsafe类在提升Java运行效率,增强Java语言底层操作能力方面起了很大的作用。Unsafe类使Java拥有了像C语言的指针一样操作内存空间的能力,同时也带来了指针的问题。过度的使用Unsafe类会使得出错的几率变大,因此Java官方并不建议使用的,官方文档也几乎没有。看看Unsafe的getAndAddInt方法的源码:
/*
* getIntVolatile和compareAndSwapInt都是native方法
* getIntVolatile是获取当前的期望值
* compareAndSwapInt就是我们平时说的CAS(compare and swap),通过比较如果内存区的值没有改变,那么就用新值直接给该内存区赋值
*/
public final int getAndAddInt(Object paramObject, long paramLong, int paramInt)
{
int i;
do
{
i = getIntVolatile(paramObject, paramLong);
} while (!compareAndSwapInt(paramObject, paramLong, i, i + paramInt));
return i;
}incrementAndGet是将自增后的值返回,还有一个方法getAndIncrement是将自增前的值返回,分别对应++i和i++操作。同样的decrementAndGet和getAndDecrement则对–i和i–操作。
10 什么是条件锁、读写锁、自旋锁、可重入锁?
- 条件锁
条件锁是指在获取锁之后发现当前业务场景自己无法处理,而需要等待某个条件的出现才可以继续处理时使用的一种锁。比如在阻塞队列中,当队列中没有元素的时候是无法弹出一个元素的,这时候就需要阻塞在条件notEmpty上,等待其它线程往里面放入一个元素后,唤醒这个条件notEmpty,当前线程才可以继续去做“弹出一个元素”的行为。代码示例如下:
public class ReentrantLockTest {
public static void main(String[] args) throws InterruptedException {
// 声明一个重入锁
ReentrantLock lock = new ReentrantLock();
// 声明一个条件锁
Condition condition = lock.newCondition();
new Thread(()->{
try {
lock.lock(); // 1
try {
System.out.println("before await"); // 2
// 等待条件
condition.await(); // 3
System.out.println("after await"); // 10
} finally {
lock.unlock(); // 11
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
// 这里睡1000ms是为了让上面的线程先获取到锁
Thread.sleep(1000);
lock.lock(); // 4
try {
// 这里睡2000ms代表这个线程执行业务需要的时间
Thread.sleep(2000); // 5
System.out.println("before signal"); // 6
// 通知条件已成立
condition.signal(); // 7
System.out.println("after signal"); // 8
} finally {
lock.unlock(); // 9
}
}
}一个线程等待条件,另一个线程通知条件已成立,后面的数字代表代码实际运行的顺序。
- 读写锁
Java提供了读写锁,在读的地方使用读锁,在写的地方使用写锁,如果没有写锁的情况下,读是无阻塞的,在一定程度上提高了程序的执行效率。Java提供的读写锁接口是java.util.concurrent.locks.ReadWriteLock,如下代码所示:
public interface ReadWriteLock {
/**
* 返回读锁
*/
Lock readLock();
/**
* 返回写锁
*/
Lock writeLock();
}提供了具体的实现类ReentrantReadWriteLock,具备如下特性:
公平性选择:支持公平和非公平(默认)两种获取锁的方式,非公平锁的吞吐量优于公平锁。
可重入:支持可重入,读线程在获取读锁之后能够再次获取读锁,写线程在获取了写锁之后能够再次获取写锁,同时也可以获取读锁。
锁降级:线程获取锁的顺序遵循获取写锁,获取读锁,释放写锁,写锁可以降级成为读锁。
- 自旋锁
自旋锁可以使线程在没有取得锁的时候,不被挂起,而转去执行一个空循环,(即所谓的自旋,就是自己执行空循环),若在若干个空循环后,线程如果可以获得锁,则继续执行。若线程依然不能获得锁,才会被挂起。使用自旋锁后,线程被挂起的几率相对减少,线程执行的连贯性相对加强。因此,对于那些锁竞争不是很激烈,锁占用时间很短的并发线程,具有一定的积极意义,但对于锁竞争激烈,单线程锁占用很长时间的并发程序,自旋锁在自旋等待后,往往毅然无法获得对应的锁,不仅仅白白浪费了CPU时间,最终还是免不了被挂起的操作 ,反而浪费了系统的资源。
可能引起的问题:
(1)过多占据CPU时间:如果锁的当前持有者长时间不释放该锁,那么等待者将长时间的占据cpu时间片,导致CPU资源的浪费,因此可以设定一个时间,当锁持有者超过这个时间不释放锁时,等待者会放弃CPU时间片阻塞;
(2)死锁问题:试想一下,有一个线程连续两次试图获得自旋锁(比如在递归程序中),第一次这个线程获得了该锁,当第二次试图加锁的时候,检测到锁已被占用(其实是被自己占用),那么这时,线程会一直等待自己释放该锁,而不能继续执行,这样就引起了死锁。因此递归程序使用自旋锁应该遵循以下原则:递归程序决不能在持有自旋锁时调用它自己,也决不能在递归调用时试图获得相同的自旋锁。
- 可重入锁
可重入锁又名递归锁,是指同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁,前提是锁对象是同一个对象。Java提供的synchronized 和 ReentrantLock 都是可重入锁,在一定程度上可避免死锁。
synchronized关键字既可以修饰同步代码块,又可以修饰同步方法。synchronized修饰的方法或代码块内部调用本类的其他synchronized修饰的方法或代码块时,是永远可以得到锁的,如下代码所示:
public static void main(String[] args) {
final Object object = new Object();
new Thread(()->{
synchronized (object){
System.out.println(Thread.currentThread().getName()+"外层加锁");
synchronized (object){
System.out.println(Thread.currentThread().getName()+"中层加锁");
synchronized (object){
System.out.println(Thread.currentThread().getName()+"内层加锁");
}
}
}
},"t1").start();
}ReentrantLock可以修饰同步代码块,而且要显式释放锁,如下代码所示:
public class Main{
static Lock lock = new ReentrantLock();
public static void main(String[] args) {
new Thread(()->{
lock.lock();
try{
System.out.println(Thread.currentThread().getName()+"外层加锁");
lock.lock();
try{
System.out.println(Thread.currentThread().getName()+"内层加锁");
}finally {
lock.unlock();
}
}finally {
lock.unlock();
}
},"t1").start();
}
}11 synchronized和ReentrantLock有什么区别,有人说Synchronized最慢,是这样吗?
-
可重入性:ReenTrantLock的字面意思就是再进入的锁,其实synchronized关键字所使用的锁也是可重入的,关于这个的区别不大。两者都是同一个线程每进入一次,锁的计数器都自增1,所以要等到锁的计数器下降为0时才能释放锁。
-
锁的实现:synchronized是依赖于JVM实现的,而ReentrantLock是JDK实现的。前者的实现是比较难见到的,后者有直接的源码可供阅读。
-
性能:在synchronized优化以前,性能是比ReenTrantLock差很多的。自从Synchronized引入了偏向锁,轻量级锁(自旋锁)后,两者的性能就差不多了。在两种方法都可用的情况下,官方甚至建议使用synchronized。
-
功能:Synchronized的使用比较方便简洁,并且由编译器去保证锁的加锁和释放,而ReentrantLock需要手工声明来加锁和释放锁,为了避免忘记手工释放锁造成死锁,最好在finally中声明释放锁。ReenTrantLock的锁细粒度和灵活度都优于Synchronized。
ReentrantLock独有的能力:
- ReentrantLock可以指定是公平锁还是非公平锁。而synchronized只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。
- ReentrantLock提供了一个Condition(条件)类,用来实现分组唤醒需要唤醒的线程们,而不是像synchronized要么随机唤醒一个线程要么唤醒全部线程。
- ReentrantLock提供了一种能够中断等待锁的线程的机制,通过lock.lockInterruptibly()来实现这个机制。
ReenTrantLock的实现是一种自旋锁,通过循环调用CAS操作来实现加锁,避免了使线程进入内核态的阻塞状态。
参考
https://www.cnblogs.com/xd502djj/p/9873067.html
https://blog.csdn.net/ch98000/article/details/126283870
https://www.zhihu.com/question/66733477/answer/1915939251
https://www.cnblogs.com/tong-yuan/p/ReentrantLock-Condition.html
https://baijiahao.baidu.com/s?id=1666270412047190730&wfr=spider&for=pc
https://www.cnblogs.com/scuwangjun/p/9098057.html
https://mrbird.cc/Java-BlockingQueue.html
本文链接:https://www.codingbrick.com/archives/1056.html
特别声明:除特别标注,本站文章均为原创,转载请注明作者和出处倾城架构,请勿用于任何商业用途。
